
En 2025, plus de 60 % des modèles d'intelligence artificielle open source partagent une même architecture : le Mixture of Experts, ou MoE. DeepSeek, Mixtral, Llama 4, Gemini, Qwen3 — les noms changent, mais le principe sous-jacent est le même. Ce n'est pas une coïncidence.
Quand un fournisseur vous annonce un modèle de « 671 milliards de paramètres », la réaction naturelle est d'imaginer une machine colossale, lente et ruineuse à faire tourner. La réalité est plus nuancée. Grâce à l'architecture MoE, ce même modèle n'active que 37 milliards de paramètres pour traiter votre requête. Le reste attend, en veille, prêt à intervenir si nécessaire.
Cet article explique ce que signifie concrètement le MoE, pourquoi cette architecture s'est imposée, et surtout ce que cela change pour les décisions que vous prenez en tant que dirigeant quand vous choisissez, déployez ou négociez un service d'IA.
Un cabinet de spécialistes, pas un généraliste omniscient
La manière la plus directe de comprendre un MoE est de penser à un cabinet médical.
Un modèle d'IA classique — dit « dense » — fonctionne comme un médecin généraliste qui mobilise l'intégralité de ses connaissances pour chaque patient, qu'il s'agisse d'une angine ou d'une fracture. Chaque consultation sollicite la totalité du réseau de neurones. C'est exhaustif, mais coûteux en calcul.
Un modèle MoE fonctionne différemment. Il ressemble à un cabinet regroupant plusieurs spécialistes — un cardiologue, un dermatologue, un orthopédiste. Quand un patient arrive, un coordinateur (dans le jargon technique, le routeur) évalue la situation et oriente le patient vers les deux ou trois spécialistes les plus pertinents. Les autres restent disponibles mais ne sont pas mobilisés.
Le résultat : le patient reçoit une prise en charge de qualité au moins équivalente, mais le cabinet n'a pas eu besoin de faire travailler tous ses médecins en même temps. Transposé à l'IA, cela signifie que le modèle produit des réponses de même qualité en n'utilisant qu'une fraction de sa capacité de calcul à chaque requête.
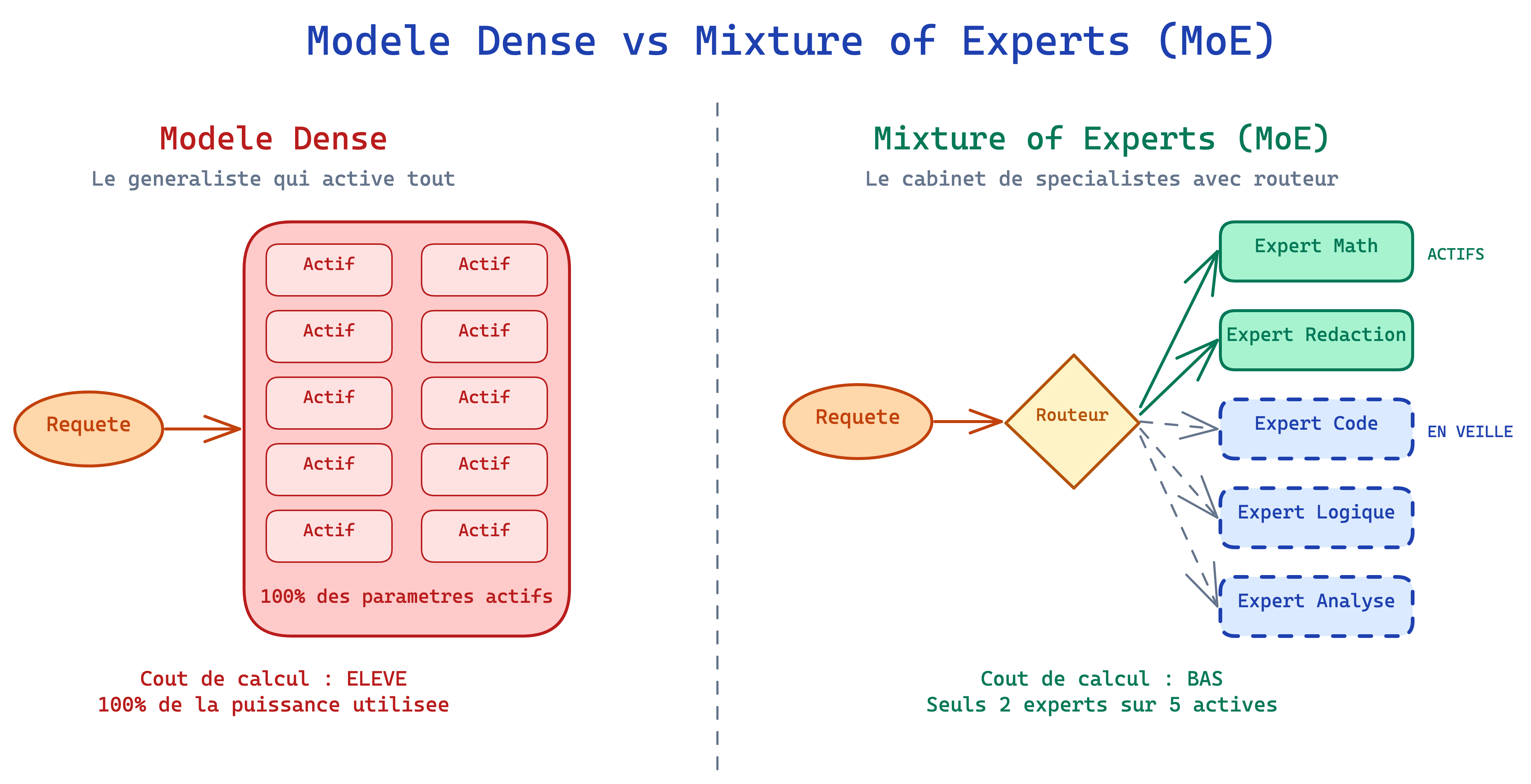
Un modèle dense active 100 % de ses paramètres. Un MoE n'active que les experts pertinents via un routeur.
Cette mécanique de routage est ce qui distingue fondamentalement les modèles MoE des modèles denses. Elle permet de construire des modèles massifs en nombre total de paramètres — donc dotés d'une connaissance étendue — tout en maintenant des coûts d'exécution comparables à ceux de modèles bien plus petits.
Le concept n'est pas récent. Les premières recherches sur le Mixture of Experts remontent aux années 1990, dans les travaux de Michael Jordan et Robert Jacobs. Mais c'est la montée en puissance des grands modèles de langage, et surtout l'explosion des coûts d'entraînement et d'inférence associés, qui a rendu cette approche incontournable. En 2022, Google a publié Switch Transformer, un modèle à 1 600 milliards de paramètres démontrant qu'un MoE pouvait être entraîné quatre à sept fois plus vite qu'un modèle dense équivalent. Le signal était lancé.
Les chiffres qui comptent
Les données concrètes illustrent l'ampleur de l'avantage.
Mixtral, le modèle qui a démocratisé l'approche MoE fin 2023, totalise 46,7 milliards de paramètres. Mais à chaque requête, seuls 12,9 milliards sont activés — soit 28 % du modèle. Résultat : Mixtral surpassait des modèles denses cinq fois plus gros, comme Llama 2 70B, tout en s'exécutant six fois plus vite.
DeepSeek-V3, sorti en décembre 2024, a poussé le concept plus loin : 671 milliards de paramètres totaux, 37 milliards actifs par requête — soit 5,5 % du modèle seulement. Son entraînement n'a nécessité que 2,8 millions d'heures GPU, une fraction du budget de ses concurrents directs. En janvier 2025, DeepSeek-R1, construit sur la même base, a égalé ou dépassé les performances des modèles d'OpenAI sur de nombreux benchmarks, tout en étant disponible en open source.
La tendance est claire et s'accélère. Le ratio de paramètres actifs par rapport au total ne cesse de diminuer :
- Mixtral (2023) : 28 % de paramètres actifs
- DeepSeek-V3 (2024) : 5,5 %
- DeepSeek V4-Pro (2026) : 3,1 %
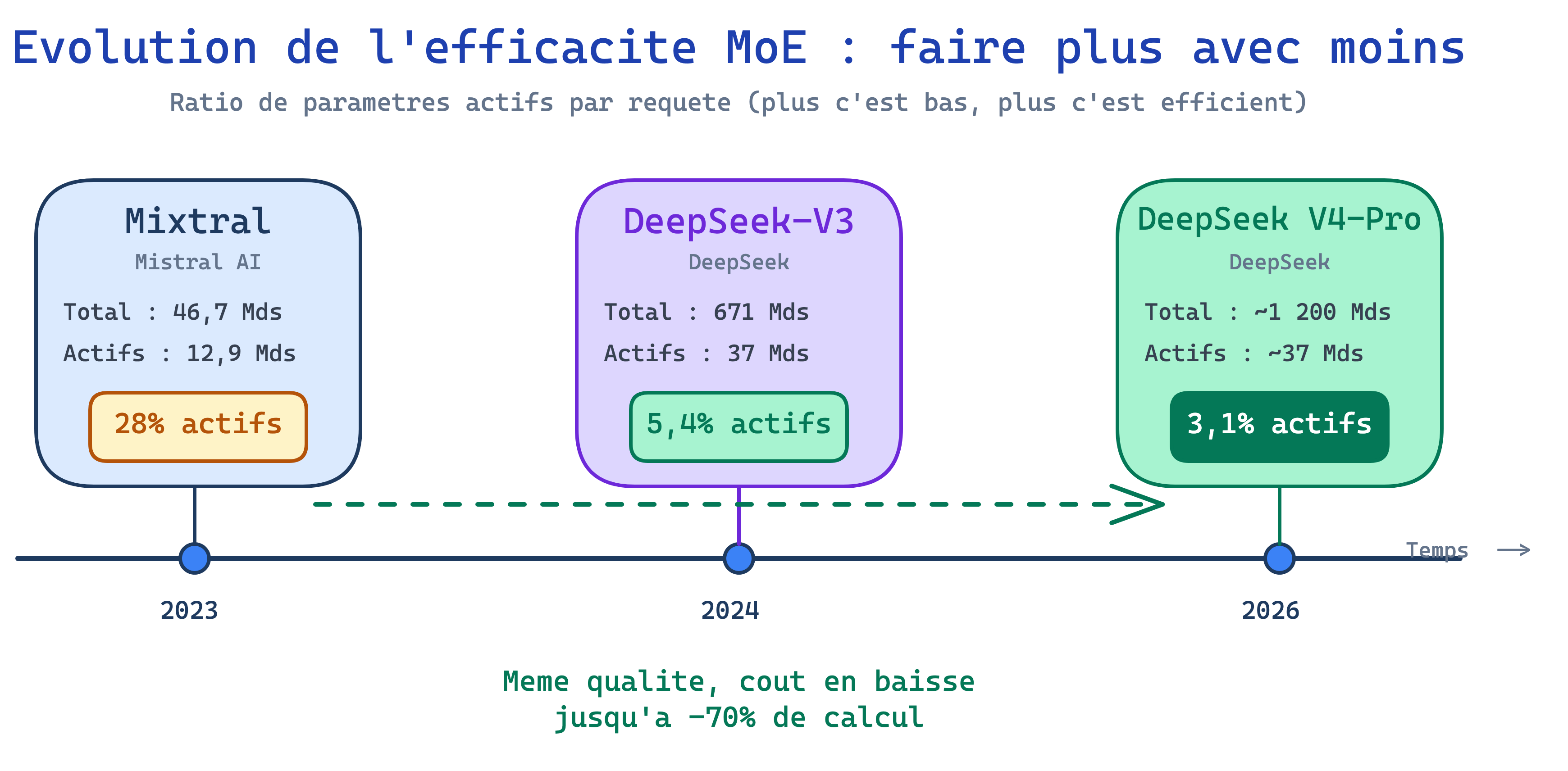
De 28 % à 3,1 % de paramètres actifs en trois ans : la tendance à l'efficience s'accélère.
Concrètement, les modèles deviennent de plus en plus grands en capacité totale, mais de plus en plus économes en calcul par requête. Les études comparatives montrent que les architectures MoE peuvent réduire les coûts de calcul jusqu'à 70 % par rapport à un modèle dense de qualité comparable.
Qui utilise les MoE aujourd'hui ?
La réponse courte : presque tout le monde.
Depuis début 2025, la quasi-totalité des modèles de pointe — qu'ils soient ouverts ou propriétaires — reposent sur une variante de l'architecture MoE :
- DeepSeek (Chine) : V3, R1, V4-Pro — la gamme complète est MoE
- Mistral AI (France) : Mixtral, puis Mistral Large 3
- Meta (États-Unis) : Llama 4 Maverick
- Google : la famille Gemini
- Alibaba (Chine) : Qwen3-235B, et la gamme Qwen3 Coder
Le cas de Qwen3-Coder-Next est particulièrement révélateur : avec 80 milliards de paramètres totaux mais seulement 3 milliards actifs, ce modèle surpasse des concurrents qui activent dix fois plus de paramètres sur des tâches de programmation.
Il existe un contre-exemple notable : la famille Claude d'Anthropic reste sur une architecture dense. Ce choix délibéré montre qu'il n'existe pas de consensus absolu — certains laboratoires estiment que la densité offre des avantages en termes de cohérence et de fiabilité des réponses. Cela confirme aussi que l'architecture MoE n'est pas une solution universelle, mais un compromis d'ingénierie avec ses forces et ses limites.
Ce qui est remarquable, c'est la vitesse d'adoption. En 2023, le MoE restait un pari architectural. Deux ans plus tard, il est devenu le choix par défaut. Pour un dirigeant, cette convergence signifie que les modèles disponibles sur le marché — ceux que vos équipes évaluent, que vos prestataires vous proposent — sont très majoritairement construits sur cette base. Ne pas comprendre le MoE revient à acheter des véhicules sans connaître la différence entre moteur thermique et électrique : vous pouvez conduire, mais vous ne pouvez pas négocier.
Ce que cela change pour votre entreprise
Au-delà de l'architecture, les conséquences opérationnelles sont directes.
Des coûts d'utilisation en baisse
Les fournisseurs d'API qui utilisent des modèles MoE répercutent une partie des économies de calcul sur leurs tarifs. À qualité de réponse comparable, le coût par token (l'unité de facturation standard des services d'IA) tend à être sensiblement inférieur sur un modèle MoE que sur un modèle dense équivalent. Quand vous négociez un contrat d'API avec un fournisseur, demander si le modèle sous-jacent est MoE ou dense n'est pas une question technique abstraite — c'est une question de marge.
L'IA puissante sur du matériel accessible
Puisqu'un MoE n'active qu'une fraction de ses paramètres, il peut tourner sur des infrastructures moins coûteuses. Des modèles qui auraient exigé des grappes de GPU haut de gamme en architecture dense fonctionnent sur du matériel grand public en architecture MoE. Pour les entreprises qui souhaitent déployer de l'IA en local — par exemple pour des raisons de confidentialité des données — cela élargit considérablement le champ des possibles.
Arrêter de compter les paramètres
Le réflexe de comparer les modèles sur leur nombre brut de paramètres est devenu trompeur. Un modèle de 671 milliards de paramètres MoE et un modèle dense de 70 milliards peuvent avoir des coûts d'exécution proches — et le premier sera probablement plus performant. Le critère pertinent est désormais le ratio paramètres actifs / qualité de sortie, pas le chiffre total affiché dans les communiqués de presse.
La logique de spécialisation
L'architecture MoE reflète un principe organisationnel que tout dirigeant connaît : la spécialisation produit de meilleurs résultats que la polyvalence à outrance. Les « experts » d'un modèle MoE se spécialisent naturellement au cours de l'entraînement — certains deviennent performants sur le raisonnement mathématique, d'autres sur la rédaction, d'autres sur l'analyse de code. C'est l'équivalent, en termes de calcul, d'une organisation qui structure ses compétences au lieu de demander à chaque collaborateur de tout savoir faire.
Un levier de négociation concret
Quand un prestataire vous facture l'accès à un modèle MoE au même prix qu'un modèle dense de taille comparable, il capte l'intégralité du gain d'efficacité pour lui-même. La connaissance de l'architecture sous-jacente devient un argument de négociation : si le modèle n'active que 5 % de ses paramètres par requête, le coût marginal pour le fournisseur est structurellement bas. Cette asymétrie d'information, que la plupart des acheteurs non techniques ignorent, représente un levier tangible dans les discussions commerciales.
Les limites à connaître
L'architecture MoE n'est pas exempte de contraintes, et les connaître évite de mauvaises surprises.
L'empreinte mémoire reste élevée. Même si seuls 37 milliards de paramètres sont actifs, les 671 milliards doivent résider en mémoire (RAM ou VRAM) pour être accessibles au routeur. Un modèle MoE consomme donc autant de mémoire qu'un modèle dense de même taille totale. L'économie porte sur le calcul, pas sur le stockage.
L'entraînement est plus complexe. Équilibrer la charge entre les experts — éviter que certains soient sur-sollicités pendant que d'autres restent inactifs — constitue un défi technique majeur. DeepSeek a développé des stratégies innovantes d'équilibrage sans perte auxiliaire pour résoudre ce problème, mais la complexité d'entraînement reste supérieure à celle d'un modèle dense.
La prévisibilité peut varier. Le routeur décide dynamiquement quels experts activer pour chaque requête. Deux requêtes similaires peuvent être traitées par des combinaisons d'experts légèrement différentes, ce qui peut introduire une variabilité dans les réponses. Pour des cas d'usage exigeant une reproductibilité stricte — conformité réglementaire, audit financier, documentation contractuelle — cette caractéristique doit être évaluée et testée avant mise en production.
Ces limites ne disqualifient pas l'architecture. Elles définissent les conditions d'un déploiement réussi. Un dirigeant informé n'évite pas les MoE à cause de ces contraintes — il dimensionne son infrastructure et ses attentes en conséquence.
Trois questions à poser à votre fournisseur IA
Vous n'avez pas besoin de comprendre les détails mathématiques du routage par softmax pour prendre de meilleures décisions. Trois questions suffisent :
- Votre modèle est-il dense ou MoE ? La réponse conditionne la structure de coûts et les performances réelles.
- Quel est le ratio paramètres actifs / paramètres totaux ? Plus ce ratio est bas, plus le modèle est efficient en calcul — à qualité égale.
- Comment cela se traduit-il sur le coût par requête ? L'efficacité architecturale doit se refléter dans la tarification. Si ce n'est pas le cas, la marge du fournisseur mérite discussion.
Le Mixture of Experts n'est pas une tendance passagère. C'est le standard architectural qui structure désormais l'industrie de l'IA générative. Comprendre son fonctionnement, même à un niveau conceptuel, c'est reprendre le contrôle sur les choix technologiques qui déterminent les coûts, la qualité et la compétitivité de vos services augmentés par l'IA.


